【Spring Boot + Kotlin】 REST APIサーバとして認証機能を実装する
最近はSpring Bootを使った個人用のWebアプリケーションを作っているが、認証機能で思った以上に苦戦中。フロントエンドはSpring Bootのtemplateを使っていないため、単純なREST APIとしてSpring Bootを使う場合どう認証をすればいいのか理解が大変だった。 今回はユーザ名とパスワードによる基本的なログイン処理を作る。JWTなどのトークンは導入せず、サーバ側でセッション管理できるようにする。
まずspring-securityを入れる。
dependencies {
implementation("org.springframework.boot:spring-boot-starter-security")
}
次にConfigurationを設定する。Spring Securityでは、実際の認証処理(ユーザ名・パスワードの照合)は AuthenticationProvider で行われる。ユーザ名・パスワード認証では DaOAuthenticationProvider で行われ、その中ではサーバに保持されているユーザの情報を 受け取るための UserDetailService と、入力されたパスワードをEncodeする PasswordEncoder が使われる。これらを定義して渡してやると認証ができるようになる。
@Configuration @EnableWebSecurity class WebSecurityConfig { @Bean fun filterChain(http: HttpSecurity, authenticationManager: AuthenticationManager): SecurityFilterChain { http { // /api/loginには認証なしでアクセス可、それ以外は要認証 authorizeHttpRequests { authorize("/api/login", permitAll) authorize(anyRequest, authenticated) HttpMethod.PUT HttpMethod.DELETE } csrf { disable() } // APIサーバなのでdisableしておく } return http.build() } @Bean fun passwordEncoder(): PasswordEncoder { return BCryptPasswordEncoder(8) } @Bean fun authenticationManager( userDetailsService: UserDetailsService, passwordEncoder: PasswordEncoder, ): AuthenticationManager { val authenticationProvider = DaoAuthenticationProvider() authenticationProvider.setUserDetailsService(userDetailsService) authenticationProvider.setPasswordEncoder(passwordEncoder) return ProviderManager(authenticationProvider) } }
UserDetailService に実装を加える。今回はデータベースの users テーブルから、ユーザ名を使ってユーザ情報を取得できるようにする。
@Service @Transactional class UserDetailServiceImpl( private val userRepository: UserRepository, ) : UserDetailsService { override fun loadUserByUsername(username: String): UserDetails { val loginUser = userRepository.findByUsername(username) ?: throw UsernameNotFoundException("User not found") return LoginUserDetails(loginUser) } }
次にDBからユーザ情報を取得する部分を実装する。以下の資料がとても参考になった。
最新の6.0で学ぶ!初めてのひとのためのSpring Security | ドクセル
UserRepositoryは以下。今回はO/R mapperとしてExposedを使っている。 UserTable の定義はテーブルのスキーマ定義があればほぼそのまま書けるので省略。
@Repository class UserRepository { fun findByUsername(username: String): LoginUser? { return UserTable.select { UserTable.username eq username } .map { LoginUser(it[UserTable.username], it[UserTable.password]) } .firstOrNull() } }
Repositoryで返している LoginUser というのは自作の型。認証のためには UserDetails を返さなければいけないが、フィールドが多くてRepositoryが知るべき情報ではないので、Repositoryの段階では簡易的な LoginUser 型を返し、それをもとにUserDetails の実装である LoginUserDetails を生成する形にする。
data class LoginUser( val username: String, val password: String, ) class LoginUserDetails(private val loginUser: LoginUser) : UserDetails { override fun getAuthorities(): MutableCollection<out GrantedAuthority> { return mutableListOf() } override fun getPassword(): String { return loginUser.password } override fun getUsername(): String { return loginUser.username } override fun isAccountNonExpired(): Boolean { return true } override fun isAccountNonLocked(): Boolean { return true } override fun isCredentialsNonExpired(): Boolean { return true } override fun isEnabled(): Boolean { return true } }
最後にログイン時に使うControllerを作る。Springのドキュメントの例を参考にする。
注意点として、今回のようにREST APIサーバとして認証を行うときは、その後にセッションを保持する処理は自分で明示的に書かなければいけない。 Spring Bootからテンプレートを使ってログインフォームを配信する場合は自動で行ってくれるらしいが、上のドキュメントには以下のような注意書きがある。
この例では、必要に応じて、認証されたユーザーを SecurityContextRepository に保存するのはユーザーの責任です。例: HttpSession を使用してリクエスト間で SecurityContext を永続化する場合は、HttpSessionSecurityContextRepository を使用できます。
セッション保持の処理はこちらのドキュメントを参考にする。
authenticationManager.authenticate() が終わった後の処理は、セッション保持のためのもの。
data class LoginRequestParams( val username: String, val password: String, ) @RestController class LoginController(private val authenticationManager: AuthenticationManager) { private val securityContextHolderStrategy = SecurityContextHolder.getContextHolderStrategy() private val securityContextRepository: SecurityContextRepository = HttpSessionSecurityContextRepository() @PostMapping("/api/login") fun login( @RequestBody loginRequestParams: LoginRequestParams, request: HttpServletRequest, response: HttpServletResponse, ) { val authenticationToken = UsernamePasswordAuthenticationToken(loginRequestParams.username, loginRequestParams.password) val authentication = authenticationManager.authenticate(authenticationToken) val securityContext = securityContextHolderStrategy.createEmptyContext() securityContext.authentication = authentication securityContextHolderStrategy.context = securityContext securityContextRepository.saveContext(securityContext, request, response) } }
これでログイン認証はできたので、APIでアクセスを試してみる。新規登録導線は作っていないので、DBに手動でユーザ名とパスワード ( PasswordEncoder で指定したのと同じ形式でハッシュ化したもの) を入れておく。
curl -X POST -H "Content-Type: application/json" -d '{"username": "Udomomo", "password": "<password>"}' http://localhost:8080/api/login -i -c cookie.txt HTTP/1.1 200 Set-Cookie: JSESSIONID=<cookie value>; Path=/; HttpOnly X-Content-Type-Options: nosniff X-XSS-Protection: 0 Cache-Control: no-cache, no-store, max-age=0, must-revalidate Pragma: no-cache Expires: 0 X-Frame-Options: DENY Content-Length: 0 Date: Sat, 25 Nov 2023 10:45:44 GMT
無事に200が返ってきて、 JSESSIONID がcookieにセットされる。
【Alfred Workflow】Script Filterで自作コマンドを開発する
せっかくAlfred Powerpackに入っているのでもっと使いこなしたいと思い、Workflowを使ってツールを作ってみた。
作ったのはこんな感じのモールス信号解読機。趣味でパズルを解いたりしていると、ふとしたときに意外と出てくるので、爆速で立ち上がるAlfredで解読したいと思っていた。

Alfred Workflowとは
Alfred Workflowを使うと、Alfredを拡張し、独自のキーワードで様々な機能を開発することができる。ただし有料ライセンスであるPowerpackを購入していることが条件。
全体の流れはGUIで作成するが、ビジネスロジックの部分はスクリプトで書くことができる。対応言語もBash, PHP, Ruby, Pythonなどいろいろある。
Script Filterを設定する
今回のツールでは、
- モールス信号を入力している間に結果がリアルタイムで下に表示され、更新されていく
- Enterキーを押すと結果がクリップボードにコピーされる
という挙動にしたかったので、Script Filterを使用した。
Script Filterはもともとは検索機能のために用意されているもので、スクリプトの実行中にAlfredに結果を表示できる。また、どのような書式で結果を表示するかもカスタマイズできる。
Script Filterを設定する
Alfred Preferenceの画面からWorkflowsを選ぶと、新しいWorkflowを開発できる。ちなみにAlfredの入力画面で alfred と入力すれば、Alfred Preferenceに飛べる。
右クリックで Inputs以下にある Script Filter を選択すると、新しいScript Filterを作成できる。また、最終結果をクリップボードに渡したいので、Outputとして Copy to Clipboardを選び、Script Filterから線をドラッグしてつないでおく。
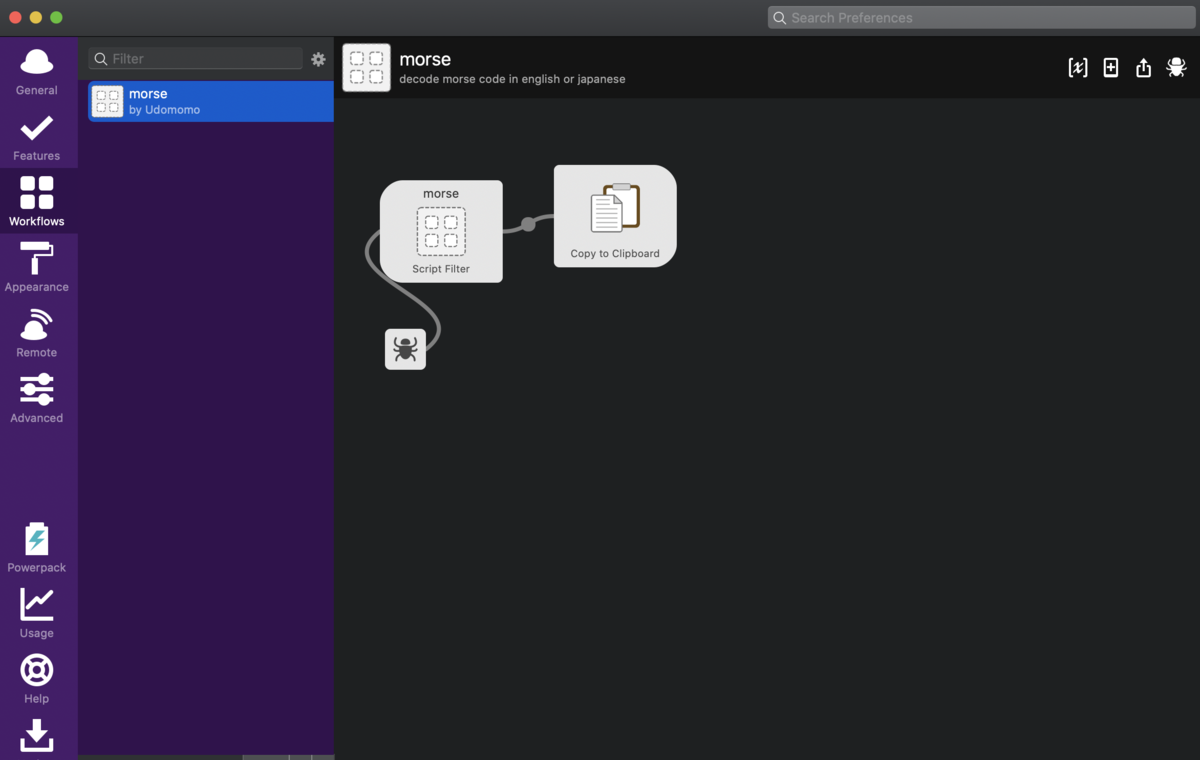
Script Filterを作成すると、以下のような設定画面になる。 Keyword の欄には、このworkflowを開始するためにAlfred上で入力するキーワードを指定する。引数はqueryとargvのどちらでも良いが、エスケープの心配がいらない点やパフォーマンス面から、Alfredではargvを推奨している。
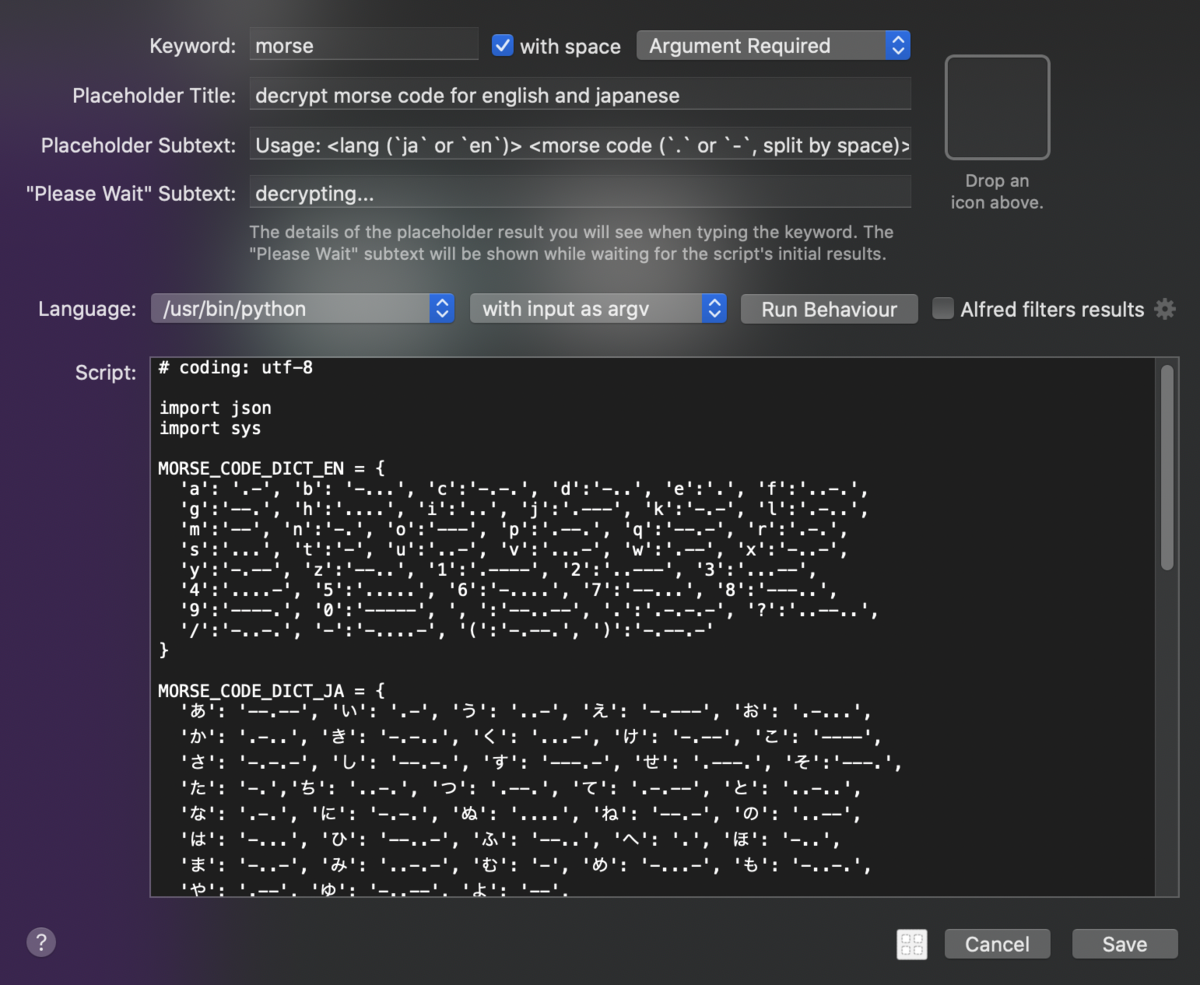
Run Behaviourからは、入力中のスクリプトの挙動を設定できる。文字をどんどん入力していったら前の段階での結果はいらなくなるので、Queue Mode は Terminate previous script にする。また、結果のリアルタイム表示といっても、入力が一段落した時点でスクリプトを実行すれば十分なので、 Queue Delayは Automatic delay after last character typed にする。

スクリプトを作成する
今回はPythonで作成した。日本語と英語の解読ができれば良かったので、モールス信号の辞書をそのまま貼ったのだが、その部分は長いので省略している。
# coding: utf-8 import json import sys MORSE_CODE_DICT_EN = { 'a': '.-', 'b': '-...', 'c':'-.-.', 'd':'-..', 'e':'.', 'f':'..-.', ... } MORSE_CODE_DICT_JA = { 'あ': '--.--', 'い': '.-', 'う': '..-', 'え': '-.---', 'お': '.-...', ... } def decrypt(lang, input): if lang == 'ja': return _morse_to_letters(input, MORSE_CODE_DICT_JA) elif lang == 'en': return _morse_to_letters(input, MORSE_CODE_DICT_EN) else: return 'Invalid argument. Usage: <lang (`ja` or `en`)> <morse code (`.` or `-`, split by space)>)' def _morse_to_letters(input, morse_dict): if not input: return 'No morse code input.' reversed_dict = {value:key for key,value in morse_dict.items()} result = '' for m in input: result += reversed_dict.get(m, '#') return result if __name__ == '__main__': args = sys.argv[1].split() lang, input = args[0], args[1:] result = { 'items': [{ 'uid': 'morse', 'title': decrypt(lang, input), 'arg': decrypt(lang, input) }] } sys.stdout.write(json.dumps(result, ensure_ascii=False))
注意すべきポイントは3つある。まず、通常のPythonスクリプトのsys.argvとは異なり、Script Filterではキーワードの後に入力した引数全てがsys.argv[1] に入る。例えば morse ja .-- --.-- と入力する場合、ja .-- --.-- がsys.argv[1]の値になる。最終的なargsの数を予測できないので当然といえば当然だが、自分はここでかなりハマった。
2つ目は、Alfred WorkflowはPython 2のみに対応していること。これはWorkflowがMacのビルトイン環境のみで動くことを重視しているためらしい。今回の場合、コード内でひらがなを使っているため、冒頭に # coding: utf-8 をつけないとエラーになった。
最後に、Script FilterからAlfredに結果を渡すためには、専用のJSONまたはXMLフォーマットに従う必要がある。JSONフォーマットは以下のページに記載されている。
複雑なWorkflowになると、専用のライブラリ(例: alfred-workflow )を使うことも多いが、今回は単純なスクリプトなので手動でJSONを作った。
{ 'items': [{ 'uid': 'morse', 'title': decrypt(lang, input), 'arg': decrypt(lang, input) }] }
uidはAlfredが結果のitemを識別するためのID(必須ではない)。titleの部分に解読結果を載せている。また、 args に指定された値は、Enterキーを押した時点でOutputに渡される。今回の場合、argsにも解読結果を指定することで、最終的な結果をクリップボードに渡すことができる。
この他にも任意のフィールドがたくさんあり、アイコンの指定などもできる。
これでいつものAlfredウィンドウから、morseコマンドが使えるようになった。
なお、Alfred Workflowにはデバッグツールも用意されているので、Script Filterが思うように動かない場合はログを確認してみよう。
AWS SysOps Administrator Associateに合格しました
少し前になってしまうが、3月末にAWS SysOps Administrator Associate試験を受験して合格した。1月末から試験勉強を始めたのだが、幸い1回で合格できた。
受験の経緯
会社のシステムがAWS上で動いており、運用のためには体系的な知識が必要だと感じたため。社内ではSolution Architect Associateの方を受験する人もいたが、自分の興味がアプリケーションというよりもミドルウェア・インフラ寄りだったため、SysOpsを選択した。
学習法
まずUdemyのコースで一通りの範囲を学習した。
このコースは実際にAWSの各サービスを利用するハンズオンが充実しており、単なる試験対策にとどまらない実践的な知識を得ることができる。ただし量が多めで、1月末から観始めて3月上旬くらいまでかかった。自分はEC2やS3・VPC等についての基本的な知識がある状態で勉強を開始したので、何も知識がない場合はもっとかかるかもしれない。
このコースには最後にmock examがついているが、実際の試験よりも難しめで細かな内容が多い。そのため、できなくてもあまり自信を失う必要はない。そのかわり、各コースの最後についている小テストは基本的な内容なので、ここは満点を取れるまで復習した。
また、模擬試験には以下のサービスを利用した。
このサービスは無料会員でも#1~#5までの5回分の模擬試験を受けられるが、有料会員になるのがおすすめ。なぜかというと、後ろの模擬試験になるほど現在の本番試験に即した問題になっているからである。自分は#86から解きはじめ、#60くらいまでを2周したのだが、本番で全く同じ問題が何問か出てきて驚いた。
本番について
試験はオンラインで自宅から受験した。予約はAWS認定の公式サイトから行う。
受験システムはPSIかピアソンを選ぶことができるが、ピアソンの場合Karabiner-Elementsが入っているPCではうまく動作しないという情報があったため、PSIを選択した。
当日は特に問題なく受験できたが、PSIは試験官とのやり取りが英語のみであるため、英語ができない人はピアソンの方が良いかもしれない。
また、他のオンライン試験同様、机の周りはあらかじめ片付けておく必要がある。自分は机の上の物はもちろん、壁のカレンダーや掲示物等もすべて剥がしたうえで臨んだのだが、机の隣に本棚があったため、試験官から場所を移動するよう命じられた(他にPCを置ける場所がなかったので、無理やり本棚を動かしてなんとかした)。机の周りに物や家具がある人は、試験当日にあらかじめ移動させておくか、試験を受けられるどこか別の場所を探しておいた方が良い。
【Kustomize】patchesJson6902の使い方と利用シーン
Kustomizeを使うとき、 patches でファイルを指定してbaseファイルを部分的に変更することが多いと思う。しかし先日、 patches ではなく patchesJson6902 という指定をしているファイルを見かけたので、どう使うのか調べてみた。
patchesJson6902とは
patchesJson6902は、名前の通りRFC6902に沿った方法でPatch処理を行うことができる。RFC6902ではJSON Patchについて定義されている。
Kustomizeは公式ドキュメントをたどりづらいが、Kubernetesのドキュメントの中に詳しい使い方が記載されている。 kubernetes.io
patchesStrategicMerge と patchesJson6902 の違い
Kustomizeでは、patchを行う際に patchesStrategicMerge と patchesJson6902 の2つの方式に対応している。 patch フィールドは渡したファイルまたはPatchをもとに、どちらの方式かを自動で判定して適用してくれる。
この2つの方式がどう違うのかというと、 patchesStrategicMerge はマージの挙動をKubernetesの設定ファイルに最適化されるように変更している。例えば、以下のようなdeployment.yamlがあるとする。
# base/deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.14.1 ports: - containerPort: 80 - name: nginx image: nginx:1.14.2 ports: - containerPort: 80 - name: nginx image: nginx:1.14.3 ports: - containerPort: 80 # base/kustomization.yaml resources: - deployment.yaml
overlaysを以下のようにする。
# overlays/test/deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: template: spec: containers: - name: busybox image: busybox:1.33 ports: - containerPort: 80 # overlays/test/kustomization.yaml bases: - ../../base patchesStrategicMerge: - deployment.yaml
このとき、buildした結果は以下のようになる。overlaysで指定したコンテナが、 containers に追加されていることがわかる。
$ kustomize build . apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: busybox:1.33 name: busybox ports: - containerPort: 80 - image: nginx:1.14.1 name: nginx ports: - containerPort: 80 - image: nginx:1.14.2 name: nginx ports: - containerPort: 80 - image: nginx:1.14.3 name: nginx ports: - containerPort: 80
一方で、これと同じことを patchesJson6902 で行おうとすると、overlaysを以下のようにしなければならない。
# overlays/test/kustomization.yaml bases: - ../../base patchesJson6902: - target: group: apps version: v1 kind: Deployment name: nginx-deployment patch: |- # patchの内容は別ファイルに指定しても良い - op: add path: /spec/template/spec/containers/0 value: {"image": "busibox:1.33", "name": "busybox", "ports": [{"containerPort": 80}]}
patch 内の path でJSON pathを指定する必要があり、ここで配列のインデックス番号を指定したうえで、配列に入れる新たな要素を定義する必要がある。 patchesStrategicMerge の場合と同じようにしてしまうと、 containers が丸々入れ替わって busybox のみになってしまう。
patchesJson6902 を使うべきシーン
逆に「配列の中の特定の一要素を入れ替えたい場合」は patchesJson6902 の方を使うべき。
# overlays/test/kustomization.yaml bases: - ../../base patchesJson6902: - target: group: apps version: v1 kind: Deployment name: nginx-deployment patch: |- - op: replace path: /spec/template/spec/containers/0 value: {"image": "busibox:1.33", "name": "busybox", "ports": [{"containerPort": 80}]}
op を replace に変更したことで、 containers 配列の0番目の要素のみを入れ替えることができる。結果は以下の通り。
$ kustomize build . apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: busibox:1.33 name: busybox ports: - containerPort: 80 - image: nginx:1.14.2 name: nginx ports: - containerPort: 80 - image: nginx:1.14.3 name: nginx ports: - containerPort: 80
これに対して patchesStrategicMerge の場合、 $patch: replace を指定することで containers 配列全体を入れ替えることはできるが、特定の要素を指定してそこだけ入れ替える機能はない。baseの containers 配列全体をoverlaysに書いてそこに新しい要素を加えるという方法はあるが、配列の要素が多い場合は非効率である。
各Patch方式の詳細な挙動は、以下が参考になる。
community/strategic-merge-patch.md at master · kubernetes/community · GitHub kustomize/inlinePatch.md at master · kubernetes-sigs/kustomize · GitHub
「レガシーコードからの脱却」を読んだ感想
昨年の10-12月まで、社内の輪読会で「レガシーコードからの脱却」を読んだ。(最初間違えて「レガシーコード改善ガイド」を買おうとしたのは内緒だ)
感想など
タイトルの通り、レガシーコードが増えていく企業ソフトウェアの開発ノウハウについて書かれた本。前半はアジャイル開発の方法論がメインで、正直この辺はより詳しいアジャイル本を読んだ方が良いと思う。しかし後半になると、単なるリファクタリングにとどまらない本質的な内容がたくさんあった。
ペアプログラミングの恐怖を乗り越える
過去に何度かペアプログラミングを行ったことがあるが、正直あまり良い印象を持っていなかった。会議室に一日中際限なく拘束されるうえに一挙手一投足を監視され、場の空気が非常に重くなりチームとしての生産性も非常に低かったからだ。
しかし8章を読んで、ペアプログラミングに対する誤解に気付かされた。良いペアプログラミングを行う前提として、「全員が問題を理解していること」そして「全員がメンターでありメンティーであること」が重要となる。ジュニアであっても時には問題解決のためにシニアに助言や意見を言うべきであり、全員が同時に問題解決にあたりディスカッションが自然と起こるような場作りが重要になる。ただ長く集まったり、交代でキーボードを打てば良いというものではない。
それでもペアプログラミングの気が進まないという人のために、本書では代替案も提示している。例えばある小さな問題を調査するために時間を区切って集まるスパイクや、1時間だけ2人が集まりお互いのその日のコードをレビューするバディプログラミングなどがある。大事なのは孤独な作業に徹することではなく、どのような形式であれチームメンバーと協力しあうこと・助けを求めることだ。
CLEANコードの意義
CLEAN原則についてはいろいろな本で目にしており頭では知っていたが、本書の9章を読むことで心で理解できた気がする。5つの原則(凝集性・疎結合・カプセル化・断定的・非冗長)は根元では全てつながり合っており、その意義は「結合すべきものは結合し、分離すべきものは分離している状態」を作り出すことにある。こうすることで、レガシーコードを最小限に抑え、ソフトウェアの保守・拡張を容易にすることができる。
また、むやみやたらに責務の分離をさせるのも良くない。12章に書かれているが、「銀行に行く」というTODOを分解して「電車の切符を買う」というような細かすぎるタスクを作る人はいない。個々のクラスの責務が過不足なく意味が通るレベルにすることで、コード全体の抽象度が揃い、責務がわかりやすくなる。
創発設計
テストファーストで実装し、常にレガシーコードにならないように気を配りながら書いていくと、責務の分割や名前などに課題が見つかっていく。これを繰り返していくと、書いている途中でより良い設計が浮かぶ。最初にすべての設計を決めてからそのとおりに実装するよりはるかにましになる。この流れを本書では「創発設計」と呼んでいる。
このやり方は初心者には厳しいものがあるかもしれないが、アジャイル開発を行っている際に仕様や実装が大きくひっくり返る経験は何度もしたことがあるので、それが言語化されてとても共感できた。
既存のアーキテクチャに無慈悲になる
最終章に少しだけ書かれていた言葉だが、非常に刺さった。自分はどうしても「既存の設計を学んで理解する」ことに意識を向けがちだが、そこで終わらず「既存の設計の問題点を理解する」ところまで行かなければ、そもそも改善しようという発想に至らない。レガシーコードを改善するためには、まず目の前にあるものがレガシーコードではないかと認識する必要がある。
改善案も既存の設計をベースにした小さなものばかりではなく、時には全く新しい設計にする方が優れたコードになるかもしれない。そのような改善には新しい知識や経験が必要になることもあり、そのために自分たちは業務内だけでなく業務外でもより多くの技術を身につける必要がある。ここは自分の大きな弱点なので、少しずつ考え方を変えていきたい。
まとめ
真新しい概念は出てこないが、今まで知っていた概念とその意義を腹落ちさせてくれる良書だった。輪読会という形式で1章ずつ精読していったことが功を奏したのかもしれない。時間がかかってもじっくり読みたい本だと思う。
【Terraform】Autoscaling GroupのLaunch Configurationを変更するのに失敗した話
先日、新しいECS ClusterをTerraformで作った。EC2インスタンスは1台のみだが、Launch Configurationを用意してAutoscaling Groupを作成した。
resource "aws_launch_configuration" "ecs_cluster" { name = "ecs_cluster" image_id = data.aws_ami.aws_optimized_ecs.id iam_instance_profile = aws_iam_instance_profile.ecs-cluster.name security_groups = [aws_security_group.ecs-cluster.id] user_data = file("${path.module}/user_data.sh") instance_type = "t3.medium" root_block_device { delete_on_termination = true encrypted = false volume_size = "30" volume_type = "gp2" } }
しかしその後、key_nameの登録を忘れておりEC2インスタンスにssh接続できないことに気づいたため、Launch Configurationを修正した。
resource "aws_launch_configuration" "ecs_cluster" {
name = "ecs_cluster"
image_id = data.aws_ami.aws_optimized_ecs.id
iam_instance_profile = aws_iam_instance_profile.ecs-cluster.name
security_groups = [aws_security_group.ecs-cluster.id]
user_data = file("${path.module}/user_data.sh")
instance_type = "t3.medium"
+ key_name = "ecs_cluster"
root_block_device {
delete_on_termination = true
encrypted = false
volume_size = "30"
volume_type = "gp2"
}
}
ところが、この状態で terraform apply しようとしても失敗してしまった。
Error: error deleting Autoscaling Launch Configuration (terraform-20201203072824459100000004): ResourceInUse: Cannot delete launch configuration terraform-20201203093824531400000001 because it is attached to AutoScalingGroup ecs_cluster
これは、TerraformがLaunch Configurationを一旦削除し、同名のものを新しく作って追加しようとしているため。 terraform plan の結果は Plan: 1 to add, 1 to change, 1 to destroy. となっており、 changeはAutoscaling Groupを、addとdestroyはLaunch Configurationを指している。
これを避けるためには2つの処理が必要となる。まず lifecycle の中で create_before_destroy = true を追加すること。通常であれば、resourceに対するupdateができない場合Terraformは古い方をdestroyしてから新しい方をcreateするが、この指定をすると先に新しいresourceのcreateが行われ、その後古い方をdestroyするようになる。これにより、Autoscaling Groupが起動しているのにLaunch Configurationがなくなってしまうということが起こらない。
もう一つは、 name の指定をやめるか、あるいは name_prefix の指定に変えること。これにより、新旧のLaunch Configurationが異なる名前を持つようになる。この指定を行わないと、同じ名前を持った新旧のresourceが一時的に併存することになってしまい、applyに失敗する可能性がある。
resource "aws_launch_configuration" "ecs_cluster" {
- name = "ecs_cluster"
+ name_prefix = "ecs_cluster_"
image_id = data.aws_ami.aws_optimized_ecs.id
iam_instance_profile = aws_iam_instance_profile.ecs-cluster.name
security_groups = [aws_security_group.ecs-cluster.id]
user_data = file("${path.module}/user_data.sh")
instance_type = "t3.medium"
key_name = "ecs_cluster"
+ lifecycle {
+ create_before_destroy = true
+ }
root_block_device {
delete_on_termination = true
encrypted = false
volume_size = "30"
volume_type = "gp2"
}
}
このようにすると terraform apply が成功した。
xargsの各オプションにおける引数の渡され方
普段xargsをよく使っているが、いつも -I オプションで引数をループさせる用途であることがほとんどなので、xargsはループ用のコマンドだと思いこんでいた。そのため先日、別の人のシェルスクリプトを読んだときに混乱してしまったのでまとめておく。
オプションなし
そもそもxargsは、標準入力として受け取ったデータをパラメータとして別のコマンドに渡すためのもの。ここでいうパラメータとは、標準入力を空白文字・改行の両方で区切ったものを指す。
デフォルトでは、xargsは受け取った全てのパラメータを1つのコマンドに対する引数として渡す。そのため、xargs以降に指定したコマンドは1回のみ実行される。
echo hoge fuga\\npiyo | xargs echo hoge fuga piyo # echo hoge fuga piyoが実行された
-I オプション
-I オプションを使うと、標準入力が改行で分割され、コマンド1回の実行につき1行ずつ使用される。そのため、xargs以降に指定したコマンドは、標準入力の行の数だけ実行されるようになる。使い所が多く便利。
for ループとの違いは、引数が1つ渡されるたびにxargs以降のコマンドが実行されること。 for ループの場合、for i in... の部分のコマンドがすべて終了し、繰り返される要素がすべて揃って始めて for ループ内部のコマンドが実行される。
echo hoge fuga\\npiyo | xargs -I {} echo {} hoge fuga # echo hoge fugaが実行された piyo # echo piyoが実行された
-n オプション
-n コマンドは、xargs以降に指定したコマンドが、最大いくつのパラメータを使えるかを指定するもの。例えば -n 1 と指定すると、パラメータが1つずつ渡され、xargs以降に指定したコマンドはパラメータの数だけ実行される。 -n 1 の場合、 -I の場合よりもさらに細かい単位で分割されることに注意。
echo hoge fuga\\npiyo | xargs -n 1 echo hoge # echo hogeが実行された fuga # echo fugaが実行された piyo # echo piyoが実行された